Giới thiệu
Dựa trên sự thành công của AlexNet vào năm 2012, nhiều nghiên cứu đã được tiến hành nhằm tìm ra các phương pháp hay kiến trúc mới để đạt được kết quả tốt hơn, ví dụ như:
- Thay đổi (tăng, giảm) kích thước của conv filter
- Thay đổi stride, padding của conv layer
- Train và test trên các input với nhiều độ phân giải (resolution) ảnh khác nhau
Trong năm 2014, VGG là một trong những kết quả nghiên cứu nổi bật nhất, và nó tập trung vào một vấn đề khác với các hướng trên là độ sâu (depth, hay là số layer) của mô hình. VGG đã đạt được các kết quả tốt nhất vào thời điểm nó ra mới trên dataset ImageNet và các dataset khác, trong các task như classification, localization,…
Ngoài ra, ta có thể đưa ra nhận xét như sau về AlexNet:
- Dù AlexNet đã chứng minh được CNN có thể đạt độ hiệu quả tốt, nó lại không cung cấp một khuôn mẫu nào cho việc nghiên cứu, thiết kế các mạng mới.
- Theo thời gian, các nhà nghiên cứu đã thay đổi suy nghĩ từ quy mô những neuron riêng lẻ sang các tầng, rồi sau đó là các khối (block) gồm các tầng lặp lại theo khuôn mẫu.
Kiến trúc của VGG là một trong những kiến trúc phổ biến đầu tiên được xây dựng theo ý tưởng như vậy.
VGG block
Điểm nổi bật của VGG là ta chỉ dùng duy nhất một kích thước filter trong mọi conv layer là $3 \times 3$, và ta dần tăng độ sâu của mô hình bằng các conv layer. Hơn nữa, ta còn áp dụng nhiều conv layer liền nhau rồi mới dùng đến max pooling. Ta có thể gọi một block gồm những layer như thế là VGG block.
- Các tác giả có đề cập đến một vấn đề cho cách áp dụng này như sau: Việc dùng nhiều conv layer 3 x 3 liền nhau như vậy so với dùng một conv layer với filter lớn hơn (ví dụ 7 x 7) như hầu hết các mô hình đã được công bố vào thời điểm trước đó thì có gì “tốt” hơn, khi mà features map sau cùng ta thu được có thể có cùng kích thước?
- Để trả lời, ta có 2 ý chính như sau:
- Giảm số lượng tham số của mô hình (đặt tính là biết nhaa 😜)
- Dùng nhiều conv layer thì ta có khả năng sẽ phát hiện được nhiều feature có ích hơn (hai conv layer sẽ tạo thành một “hàm hợp”), từ đó decision function sẽ ok hơn.
Ngoài ra, VGG block sử dụng padding 1 (giữ nguyên kích thước input), theo sau đó là max pooling với pool size $2 \times 2$ và stride 2 (giảm kích thước input đi một nửa). Kiến trúc của nó có thể được mô tả như hình bên dưới:

VGG block
Nguồn: Dive intro AI
Trong các bài toán áp dụng VGG, đôi khi ta có thể gặp VGG block với một conv layer $1 \times 1$ ở trước max pooling. Block dạng này thường được sử dụng với mục đích chính là bổ sung thêm một phép biến đổi tuyến tính nữa. Tuy nhiên, trong thực nghiệm thì các tác giả đã cho thấy rằng việc sử dụng block dạng này không hiệu quả hơn so với toàn các conv layer với filter $3 \times 3$ (cùng số lượng layer).
Kiến trúc VGG
Bằng cách kết hợp nhiều VGG block với nhau, các tác giả đã tạo ra nhiều phiên bản VGG khác nhau, với số layer có trọng số là trong đoạn 11 - 19. Trong paper VGG, ta có 6 kiến trúc với độ sâu tăng dần và tiến hành so sánh với nhau. Điểm chung của các kiến trúc này là phần fully connected đều có 3 layer, và toàn bộ layer đều sử dụng activation ReLU.

Các phiên bản VGG
Ta có một số nhận xét như sau:
- Số lượng conv layer trong các VGG block của các phiên bản là tăng dần.
- Để ý đến B, C và D thì:
- C = B + conv layer $1 \times 1$ trong mỗi VGG block
- D = C + đổi conv layer $1 \times 1$ thành $3 \times 3$
- Khi thực nghiệm, ta có B < C < D. Do đó, việc thêm phép biến đổi tuyến tính bằng conv layer $1 \times 1$ giúp mô hình hoạt động tốt hơn, nhưng nó vẫn không bằng với việc là ta thêm luôn conv layer $3 \times 3$ 🤔.
- Độ rộng (số channel) trong từng block được tăng theo bội 2. Ý tưởng này được sử dụng rất rộng rãi trong thời điểm này và cả về sau
- Để hạn chế overfitting, ta có thể sử dụng thêm dropout cho hai tầng fully connected đầu tiên.
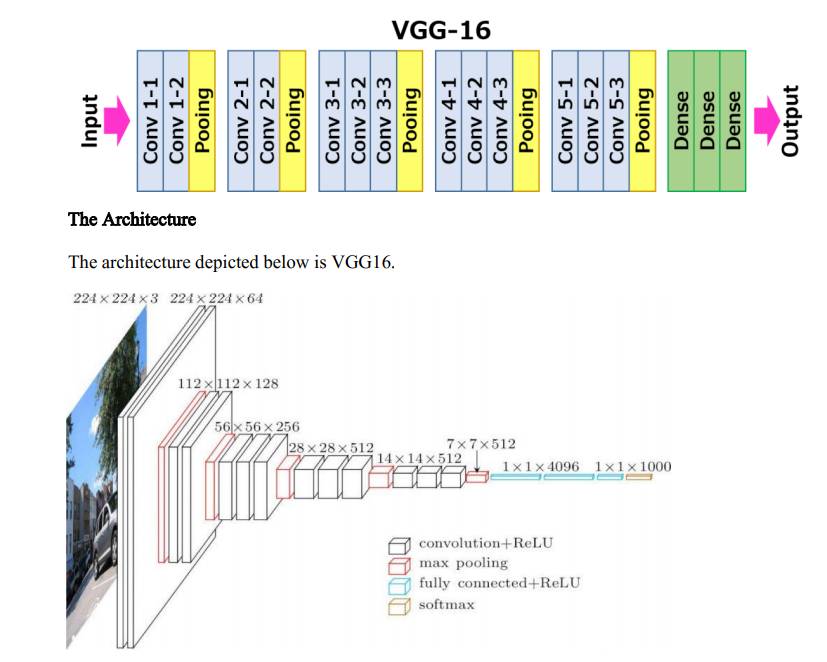
Hai kiến trúc phổ biến nhất trong việc áp dụng VGG vào các bài toán khác là D (VGG16) và E (VGG19). Để trực quan hơn, ta có thể thể biểu diễn VGG16 như sau:


{kind=link}
{kind=link}
Cài đặt
Các bạn có thể tham khảo phần cài đặt VGG bằng Tensorflow và Pytorch tại repo sau.