Note. Vì gần đây mình bận khá nhiều việc nên blog đang bị “đóng băng” 🥲 Bài viết này chỉ mang tính chất chữa cháy sau hơn 1 tháng không có bài mới (đây là bài đã được viết sẵn từ trước) =))
Tuy nhiên, MLP Mixer cũng là một mô hình này cũng rất thú vị. Chỉ hơi tiếc một chút là mình lại post nó trước khi viết những bài về Transformer và Vision Transformer…
Giới thiệu
Vào thời điểm năm 2021, có thể nói rằng nhắc tới các mô hình trong Computer Vision thì ai ai cũng nghĩ đến một là CNN, hai là các mô hình dựa trên Transformer đang làm mưa làm gió với những mô hình mạnh mẽ như Vision Transformer hay Swin Transformer.
Giữa tình hình đó, một mô hình được công bố mà khi nghe qua là ta đã thấy khó mà tin được là nó tốt đến thế. MLP-Mixer, mô hình chỉ sử dụng các fully connected layer, hệt như thời “xa xưa” ta dùng để xây dựng các Deep Neural Network (DNN), hay còn lại là Multi-layer Perceptrons (MLP) 😀
Multi-layer Perceptron
Trước hết, ta cùng nhắc lại đến những hạn chế khiến DNN trở nên không phù hợp với computer vision và gần như đã bị bỏ quên khi CNN được phát triển:
- DNN dễ bị overfitting
- Số lượng tham số của một mô hình DNN là rất lớn
- Nó khó học được những đặc trưng liên quan sự dịch chuyển vị trí trong không gian Ví dụ, xét 4 bức ảnh chứa cùng một con chó như ở bên dưới thì khi các ảnh này được đưa vào DNN để tính toán, ta sẽ có các vector rất khác nhau. Trong khi đó, với CNN, qua các lần sử dụng filter thì ta sẽ thu về được các feature map tương tự nhau.

Ví dụ về sự quan trọng của các đặc trưng liên quan đến sự dịch chuyển vị trí trong không quan
Như vậy, ta dễ hiểu rằng mô hình MLP-Mixer mà bài viết này giới thiệu sẽ có các cách để khắc phục được những vấn đề đó. Lưu ý rằng, MLP-Mixer không phải là SOTA khi nó được công bố và nó vẫn còn kém một chút so với Vision Transformer. Tuy nhiên, xét đến tốc độ thì MLP-Mixer nhanh hơn khá nhiều.
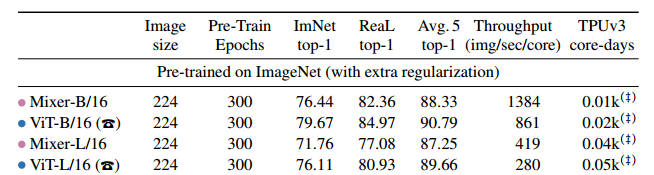
So sánh MLP-Mixer và Vision Transformer trên tập ImageNet
Chia ảnh input thành các phần nhỏ
Nếu đã từng xem qua các mô hình dựa trên Transformer trong Computer Vision thì ta cũng đã rất quen thuộc với bước này. Ảnh input $H \times W \times C$ của mô hình sẽ được chia thành các patch (hay là token) nhỏ có kích thước bằng nhau là $P \times P \times C$. Giá trị của $H$, $W$ và $P$ thường được chọn sao cho ta chia vừa đủ số patch, và $H$ thường bằng $W$. Như vậy số patch mà ta có được là
$$ S = \frac{H \times W}{P^2} $$

Chia ảnh input thành các tokens (hay patches)
Sau đó, ta sẽ duỗi những patch có được này để làm input cho mô hình. Lúc này, một ma trận input của ta sẽ có shape là $(S, P \times P \times C)$, với mỗi hàng là “đặc trưng” ban đầu của mỗi patch. Ở các phần tiếp theo, ta gọi $P \times P \times C$ là số “channel” của một token, và ta kí hiệu nó là $C$ (hơi lú chút 😅)

Minh họa ma trận input
Channel-mixing và token-mixing
Ý nghĩa
Trong MLP-Mixer, các tác giả giới thiệu hai block đặc biệt là channel-mixing và token-mixing. Đây cũng chính là những gì tinh hoa nhất trong MLP-Mixer.
Ta có thể mô tả hai block này như sau:
- Channel-mixing: Liên quan đến quan hệ giữa các channel trong cùng một token, tức là các hàng của ma trận input. Nó thực hiện phép toán kết hợp những giá trị trên các channel của cùng một patch và có sự độc lập giữa các patch, do đó ta gọi nó là channel-mixing.
- Token-mixing: Liên quan đến quan hệ giữa các giá trị ở cùng một vị trí trong các token, tức là các cột của ma trận input. Ta thấy rằng các giá trị tại cùng một vị trí trên các patch (token) được kết hợp với nhau và nó độc lập giữa các channel, do đó ta gọi nó là token-mixing.
Sự khác biệt giữa channel-mixing và token-mixing trong khi cài đặt chỉ đơn giản là input của chúng. Với channel-mixing, ta dùng luôn ma trận input có shape là $(S, C)$, còn với token-mixing thì ta cần chuyển vị ma trận input thành shape $(C, S)$.
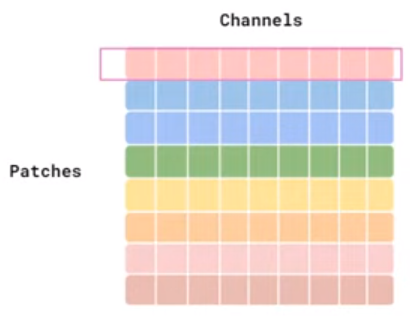
Minh họa input của Channel-mixing
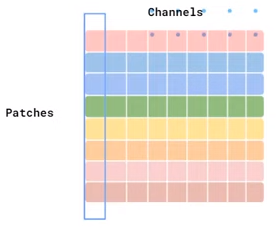
Minh họa input của Token-mixing
Block channel-mixing và token-mixing sẽ bao gồm một MLP với hai fully connected layer và chúng sử dụng GELU activation function (sẽ được ở phần tiếp theo). Trước khi tiến hành tính toán, ta sẽ đưa ma trận input qua một layer chuẩn hóa để đưa ma trận này về phân phối chuẩn tắc. Hơn nữa, ta cũng áp dụng skip connection để tăng hiệu quả training.
Kiến trúc của về channel-mixing và token-mixing như sau:
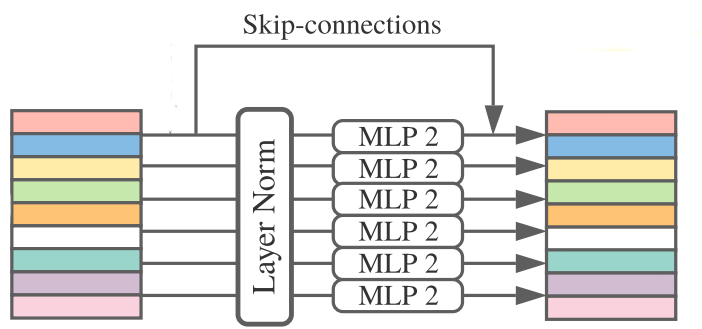
Kiến trúc của Channel-mixing
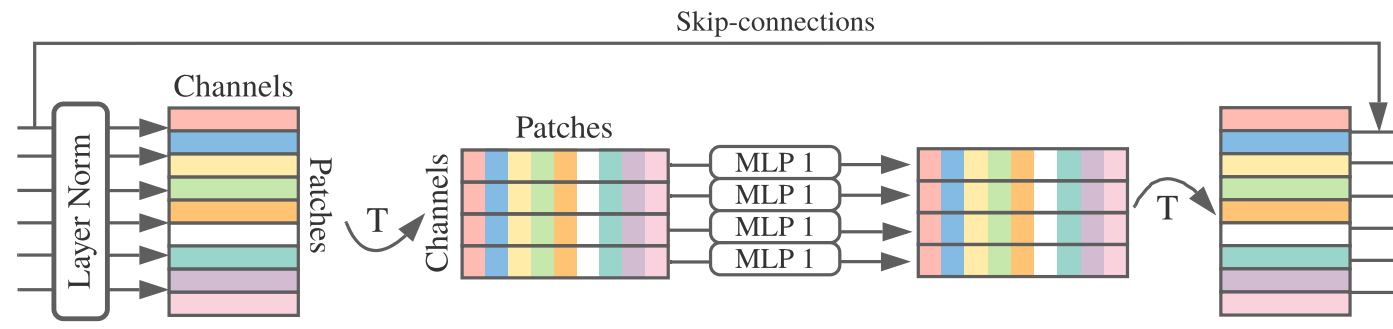
Kiến trúc của Token-mixing
Có một số điểm cần lưu ý như sau:
- Các phần “MLP1” và “MLP2” ở hai hình trên được ghi theo từng khối dọc có nghĩa là ta đã chia sẻ trọng số giữa các vector input. Yếu tố này sẽ được đề cập ở những phần sauSS
- Trong token-mixing, trước khi tính toán thì ta cần chuyển vị ma trận input
Vấn đề tiếp theo ta cần quan tâm là channel-mixing và token-mixing giúp cho MLP-Mixer đạt ược những gì.
Kết hợp đặc trưng
Các mô hình trong Computer Vision thường kết hợp các đặc trưng như sau với nhau:
- Đặc trưng tại một vị trí nào đó trong không gian
- Đặc trưng giữa các vị trí khác nhau trong không gian
Ví dụ:
- Với CNN điều này được thực hiện nhờ vào các phép toán convolution với filter $K \times K$ và pooling, mà cụ thể hơn thì ta thực hiện được (2) khi $K > 1$, và thực hiện được (1) khi $K = 1$.
- Với mô hình dựa trên Transformer thì cả 2 đều được thực hiện nhờ các self-attention layers.
- Khi xét đến MLP thông thường, ta chỉ thực hiện được (1)
Ý tưởng đằng sau MLP-Mixer là sử dụng channel-mixing cho yếu tố (1), thật sự là vậy vì channel-mixing tính toán trên từng patch độc lập; và sử dụng token-mixing cho yếu tố (2), token-mixing đã tính toán trên các patch.
Chia sẻ trọng số
Chia sẻ trọng số (typing weights) là một yếu tố giúp cho MLP-Mixer giảm được đáng kể số lượng trọng số của mô hình, đồng thời góp phần hỗ trợ việc học các đặc trưng liên quan đến tính không gian.
Xét phép toán convolution, ta sẽ thấy rằng phép toán này có sự chia sẻ trọng số trong từng channel như sau:
- Với mỗi channel của input, ta sẽ dùng một filter $K \times K$ (có $K^2$ trọng số) và lần lượt di chuyển nó qua các vị trí trên channel này để tính toán ra một feature map. Như vậy, toàn bộ các vùng trên input đều được áp dụng cùng một bộ trọng số để tính ra feature map.
- Nhờ vào việc chia sẻ trọng số, nếu một đối tượng xuất hiện ở những vị trí khác nhau trên ảnh input thì feature map ta thu được cũng sẽ rất tương tự nhau.
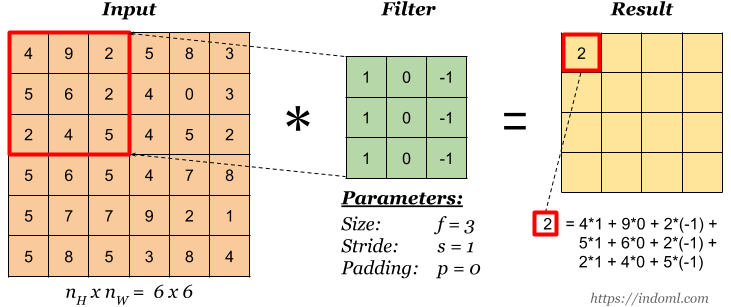
Phép toán convolution
Để ý rằng, ta sẽ không tìm thấy sự chia sẻ trọng số ở MLP thông thường. Lý do là vì mỗi neuron trong một layer của mô hình sẽ nối với toàn bộ các neuron ở layer phía trước, do đó ta có một ma trận trọng số với mỗi dòng là một vector trọng số ứng với một neuron.
Vậy trong MLP-Mixer thì chia sẻ trọng số xảy ra ở đâu?
- Với ý tưởng rất giống với filter trong CNN, channel-mixing sẽ được áp dụng chia sẻ trọng số. Việc kết hợp đặc trưng trên từng patch sẽ được tiến hành bởi cùng một bộ trọng số (ở đây là vector).
- Đối với token-mixing thì MLP-Mixer cũng áp dụng chia sẻ trọng số. Tuy nhiên, yếu tố này là rất hiếm thấy trong các nghiên cứu trước đó. Lí do chính của điều này là nhằm giảm số lượng trọng số của mô hình. Các tác giả cugx cho biết rằng họ đã thử nghiệm cả hướng không áp dụng sự chia sẻ trọng số cho token-mixing và kết quả thì rất xấp xỉ nhau.
Do đó, ở phần giới thiệu channel-mixing và token-mixing thì ta quan sát thấy cách biểu diễn phần MLP theo từng khối “MLP2” và “MLP1” như vậy.
GELU activation function
Một điểm đáng chú ý ở trong MLP-Mixer là mô hình này có sử dụng activation function GELU. Đây là một hàm sử dụng hàm phân phối tích lũy chuẩn tắc $N(0, 1)$. Có thể nói GELU là một phiên bản “trơn hơn” của ReLU.
Với giả sử input $X$ tuân theo phân phối $N(0, 1)$, ta có
$$ \text{GELU}\left(x\right) = x{P}\left(X\leq{x}\right) = x\Phi\left(x\right) = x \cdot \frac{1}{2}\left[1 + \text{erf}(x/\sqrt{2})\right], $$
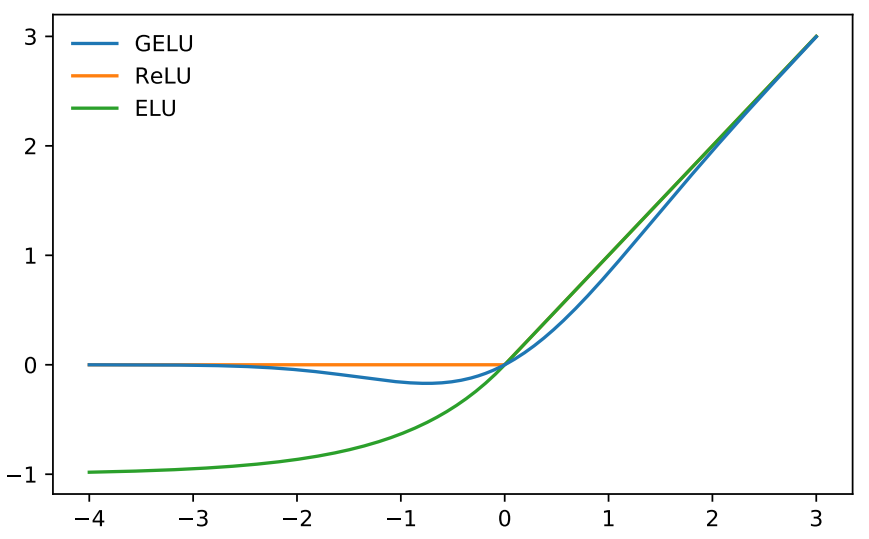
So sánh ReLU, ELU và GELU
Mixer block
Mixer block (hay Mixer Layer) là thành phần chính trong kiến trúc của MLP-Mixer. Trong block này, ta sẽ sử dụng cả channel-mixing và token-mixing, tạo nên kiến trúc như sau:

Kiến trúc của Mixer block
Như vậy, ban đầu ta sẽ áp dụng token-mixing và sau đó dùng kết quả để làm input cho channel-mixing.
Kiến trúc MLP-Mixer
Mô hình MLP-Mixer được xây dựng bằng cách áp dụng nhiều Mixer Block (hay Mixer Layer). Trước đó, ta chia ảnh input thành các patch và đưa các patch này qua một fully connected layer để giảm số channel mỗi patch. Lưu ý rằng, ở layer này thì ta cũng áp dụng sự chia sẻ trọng số, tức là toàn bộ patch đều được giảm số channel với cùng một bộ trọng số.
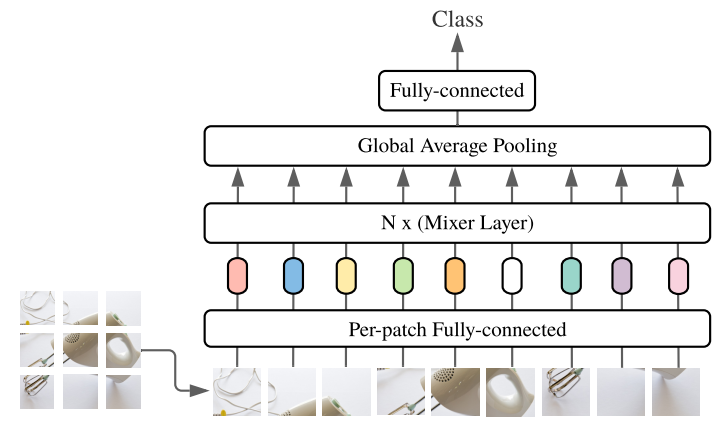
Kiến trúc của mô hình MLP-Mixer
Ngoài ra, tùy vào kích thước của một batch và số lượng Mixer Block được sử dụng mà ta sẽ có các phiên bản MLP-Mixer khác nhau. Bên cạnh các siêu tham số đó thì ta cũng có một vài siêu tham số khác như trong bảng dưới đây:

Các phiên bản MLP-Mixer. Trong đó, S, B, L và H lần lượt là Small, Base, Large và Huge. Các siêu tham số này được gán giá trị cho ảnh input với độ phân giải là 224 x 224.
Tài liệu tham khảo
- ProtonX: AI Papers Reading and Coding - MLP-Mixer: An all-MLP Architecture for Vision
- Paper MLP-Mixer: https://arxiv.org/pdf/2105.01601.pdf
- MLP-Mixer - Hướng giải quyết các bài toán Computer Vision mới bên cạnh CNN và Transformer
Lưu ý. Nếu phần Comment không load ra được thì các bạn vào DNS setting của Wifi/LAN và đổi thành "8.8.8.8" nhé (server của Google)!